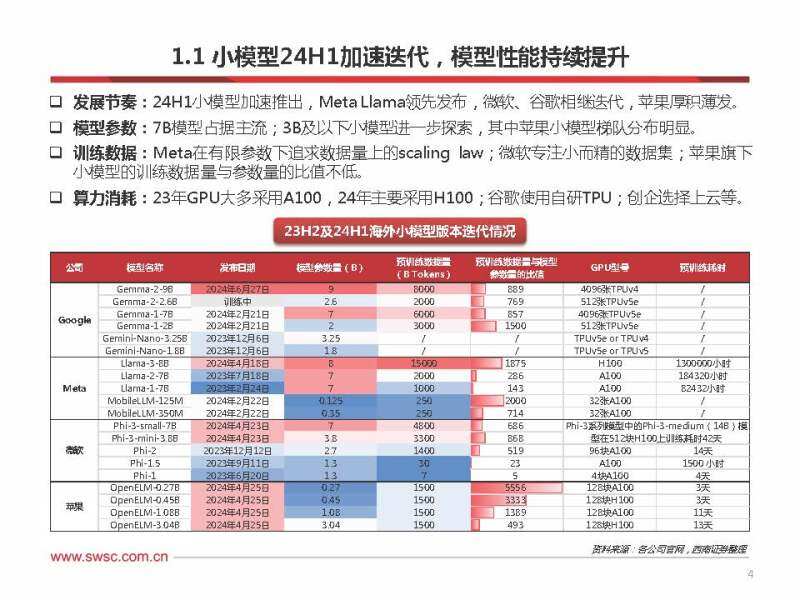
小模型24h1加速迭代,模型性能持续提升
发展节奏:24h1小模型加速推出,meta llama领先发布,微软、谷歌相继迭代,苹果厚积薄发。 模型参数:7b模型占据主流;3b及以下小模型进一步探索,其中苹果小模型梯队分布明显。 训练数据:meta在有限参数下追求数据量上的scaling law;微软专注小而精的数据集;苹果旗下 小模型的训练数据量与参数量的比值不低。 算力消耗:23年gpu大多采用a100,24年主要采用h100;谷歌使用自研tpu;创企选择上云等。
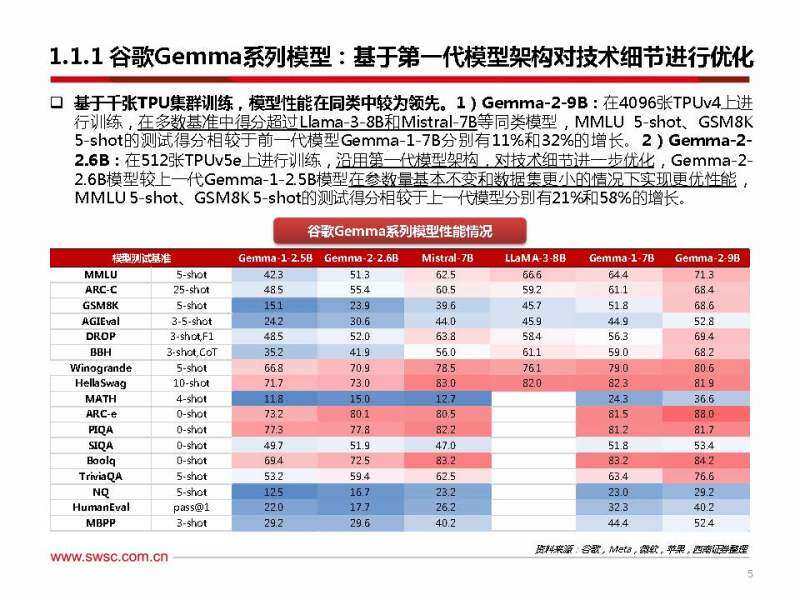
谷歌gemma系列模型:基于第一代模型架构对技术细节进行优化
基于千张tpu集群训练,模型性能在同类中较为领先。1)gemma-2-9b:在4096张tpuv4上进 行训练,在多数基准中得分超过llama-3-8b和mistral-7b等同类模型,mmlu 5-shot、gsm8k 5-shot的测试得分相较于前一代模型gemma-1-7b分别有11%和32%的增长。2)gemma-2- 2.6b:在512张tpuv5e上进行训练,沿用第一代模型架构,对技术细节进一步优化,gemma-2- 2.6b模型较上一代gemma-1-2.5b模型在参数量基本不变和数据集更小的情况下实现更优性能, mmlu 5-shot、gsm8k5-shot的测试得分相较于上一代模型分别有21%和58%的增长。
谷歌gemini-nano系列模型:部分任务性能距gemini pro较小
专为设备部署而设计,擅长总结和阅读理解。2023年12月6日,谷歌发布gemini系列自研大模型, 参数规模从大至小分别为gemini-ultra、gemini-pro、gemini-nano,其中gemini-nano模型包 括两种版本,nano-1参数规模为1.8b,nano-2为3.25b,旨在分别针对低内存和高内存的设备。
gemini-nano-1和nano-2模型与参数规模更大的gemini-pro模型对比来看:1)根据boolq基 准(主要用于衡量模型理解问题和回答问题的逻辑能力)得分,gemini-nano-1的准确率为71.6%, 性能是gemini-pro的81%,gemini-nano-2的准确率为79.3%,是gemini-pro的90%,更接近 gemini-pro的性能;2)tydiqa(goldp)基准涉及回答复杂问题的能力,gemini-nano-1和 gemini-nano-2的准确率为68.9%和74.2%,分别是gemini-pro的85%和91%,性能差距较小。
gemini-nano-1和gemini-nano-2模型对比来看:随着模型参数规模从nano-1的1.8b增加至 nano-2的3.25b,模型的性能表现在大多数任务性能均能得到提升。
meta llama系列模型:在有限参数下追求数据上的scaling law
同等参数情况下性能大幅提升,较小模型可以通过扩大训练数据量实现优秀性能。1)对比同等参 数模型来看,llama-3的8b和70b模型相对于llama-2的7b和70b模型性能均得到大幅提升。2)对 比llama-3-8b和llama-2-70b来看,在算力消耗基本持平的情况下,更好的模型性能可以通过在 更大规模的数据集上训练实现,llama-3-8b模型的参数量约为llama-2-70b的1/9,但训练数据集 是其7.5倍,最终的模型效果基本可与70b的模型相匹敌,且经过指令微调后,指令微调模型llama3-8b明显超过llama 2 70b。
meta mobilellm系列模型:强调小模型的深度比宽度更重要
模型参数进一步缩小,模型架构追求深而窄。mobilellm的模型参数仅为1.25亿和3.5亿,其技术 报告聚焦于少于10亿参数的sub-billion(<1b)模型,强调模型架构对小模型的重要性,认为模型 深度比宽度更重要,并引入分组查询注意力机制等优化技巧,相较于同类125m/350m大小模型的 基准测试得分相比,mobilellm的平均分均有提高。1)zero-shot常识推理任务方面:在125m 参数量级下,mobilellm的模型性能显著优于opt、gpt-neo、calaclafa等其他模型;在350m 参数量级下,mobilellm的各项测试得分均优于此前最先进的模型opt-350m。2)问答和阅读理 解 任 务方 面 :根据在tqa问 答的benchmark和race阅 读 理解 的benchmark的测 评结 果, mobilellm-125m和mobilellm-350m模型的精度比同等量级的小模型要高出较多。
微软phi系列模型:主要创新在于构建教科书质量的训练数据集
训练数据追求小而精,模型参数逐步扩大。2023年6月,微软发布论文《textbooks are all you need》,用规模仅为7b tokens的“教科书质量”的数据集,训练出1.3b参数、性能良好的phi-1 模型。此后,历代phi模型沿用“textbooks are all you need”的训练思想,进一步使用精挑细 选的高质量内容和过滤的web数据来增强训练语料库,以提升模型性能。在最新迭代的模型中, phi-3-mini-3.8b通过3.3t tokens的训练,在学术基准和内部测试上可与经过15t tokens训练的 llama-3-in-8b模型相匹敌。
模型架构持续优化,压缩技术不断创新
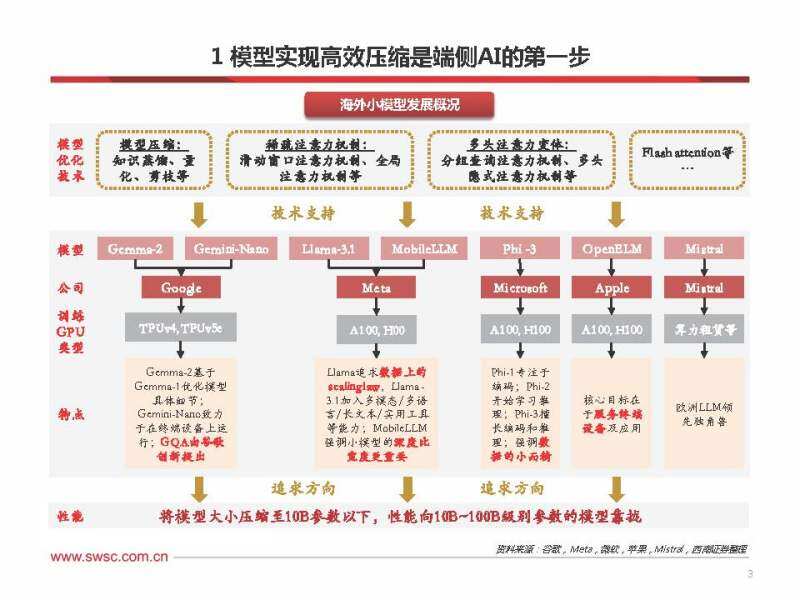
为压缩模型大小、在保持较小模型尺寸的同时实现高性能、以及能够支持较长的上下文,各海外模 型厂商纷纷布局小模型,并在模型算法优化方面进行积极探索,于24h1呈现出多种技术创新方向, 主要集中在模型压缩技术,稀疏注意力机制、多头注意力变体三大领域。
模型压缩技术:参数量化运用广泛,知识蒸馏热点较高
模型压缩技术持续发展,助力端侧部署。模型压缩技术旨在保持模型基本性能的情况下降低对推理 算力的需求,主要包括三种方法:1)参数剪枝(pruning):删除部分权重参数、去除神经网络 中的冗余通道、神经元节点等;2)参数量化(quantization):将浮点计算转成低比特定点计算, 业内应用普遍;3)知识蒸馏(knowledge distilling):将大模型作为教师模型,用其输出训练 出一个性能接近、结构更简单的学生模型,由geoffrey hinton等人在2015年谷歌论文《distilling the knowledge in a neural network》中提出,目前关注较高,业内通常使用gpt-4和claude-3 作为教师模型。
多头注意力变体:减少注意力头数量,降低内存占用
kv cache:通过缓存中间计算结果,以“内存空间”换“计算时间”。当前,主流的大语言模型 基本采用transformer decoder-only架构,其推理过程主要包括预填充和解码阶段。1)预填充阶 段:根据用户提出的prompt,生成第一个token;2)解码阶段:在生成第一个token之后,开始 采用自回归方式逐个生成后续的token,每个token的生成均需要依赖并attention此前的token, 因此,随着解码过程的进行,需要向此前生成的token的关注会越来越多,计算量也逐渐增大。 为减少解码过程中的重复计算,可以通过引入kv cache,即缓存中间结果、在后续计算中直接从 cache中读取而非重新计算,从而实现“以空间换时间”,使显存占用增加、但计算需求减少。
稀疏注意力机制:选择性处理信息,降低计算需求
稀疏注意力(sparse attention)机制:选取一部分信息进行交互,节省注意力机制成本。在当前主 流模型架构transformer中,注意力矩阵可以通过限制query-key对的数量来减少计算复杂度,即 将注意力机制稀疏化。稀疏注意力机制主要采用基于位置信息和基于内容的稀疏化方法,其中,基 于位置信息的稀疏注意力方法更加主流,主要包括全局/带状/膨胀/随机/局部块五种类型。近年来, 随着大语言模型的加速发展,计算和存储压力增大,使得稀疏注意力机制不断优化,逐步衍生出基 于以上稀疏注意力机制的复合模式,涌现出longformer等稀疏注意力模型。
从小模型论文看端侧硬件瓶颈——内存容量
将llm装进终端要求手机内存有多少dram容量? 苹果在其发布的论文《llm in a flash》中指出:在通常的llm推理阶段,llm直接加载至dram 中,一个7b参数、半精度的llm,完全加载进dram所需的存储空间超过14gb。考虑到目前主流 手机的dram最高也就16gb的水平,在端侧直接使用dram来加载7b llm面临巨大挑战。 通常一个应用最多可以占用多少dram内存? meta在其mobilellm模型论文中指出:将8-bit量化权重下的llama-2-7b模型整合至手机,内存 代价过高,手机目前dram容量从iphone 15的6gb到google pixel 8 pro的12gb不等,由于 dram需要与操作系统和其他应用程序共享,一个移动应用不应超过dram的10%(即1~2gb)。 微软在其phi-3模型技术报告中指出,phi-3-mini可在手机上实现本地推理,在3.8b尺寸、在量化 为4-bit权重下,大约占用1.8gb的内存。
从芯片厂商布局看硬件升级趋势——先进制程
手机芯片采用先进制程,工艺有望向3nm迈进。23q4,高通和联发科分别在其10月和11月峰会上 发布旗下手机芯片骁龙8gen3和天玑9300,两者均采用台积电4nm制程工艺。根据高通和联发科历 年一年一迭代的发布节奏,骁龙8gen4和天玑9400手机处理器可能于24q4推出,并有望基于台积 电3nm工艺打造。而苹果相较于其他手机芯片厂商工艺更为领先,于23q3率先推出采用3nm制程 的iphone芯片a17 pro,未来有望在先进制程上保持领先。
ui模型:手机界面理解能力提升,任务设计为人机交互奠定基础
发展节奏对比:苹果推进加速,谷歌尝试较早。1)苹果:面对日益激烈的ai竞争,苹果于23年10 月推出第一代可理解指代和定位的多模态大模型ferret,24年4月提出可以处理更高分辨率图像的改 进版本ferret-v2,以及专门针对手机用户界面的多模态大模型ferret-ui,赋予ai理解和操作应用界 面的能力。2)谷歌:由于llm作为大语言模型,通常无法直接理解ui界面,谷歌针对这一痛点, 于2022年9月和10月发表spotlight和pix2struct相关论文,对终端ui界面的理解进行初步探索; 2024年2月,谷歌推出ui模型screen ai,完善相关布局。目前,大语言模型(llm)难以直接理解 手机ui界面,应用形态以chatbot为主,而谷歌screen ai和苹果ferret-ui采用多模态视觉语言模 型(vlm),实现对屏幕信息的理解,为用户与终端设备之间的交互提供ui理解基础。
系统级ai:云端模型补充交互体验,系统升级支持更多ai场景
moe架构集成多个专家模型,处理任务专业高效。moe模型(mixture-of-experts model)即混 合专家模型,作为大模型架构的一种,moe基于“术业有专攻”的设计思想,由多个子模型(专家 模型)组成,通过将任务分门别类、再分配给不同的专家模型,使处理问题更加灵活高效;而稠密 模型(dense model),偏向于“通才”模型,能够处理众多任务,但专业能力可能不及moe。
云端模型补充端侧ai能力,moe架构可适配于多种场景。近半年来,海外模型厂商纷纷采用moe架 构,其中,谷歌基于过去的领先研究在gemini-1.5-pro模型中采用moe架构,苹果基于moe架构对 mm1模型进行扩展,且两者分别应用于苹果和三星手机的ai系统中。此外,由于moe模型中的每 个子模型能够专注处理某类特定任务,因此,手机厂商可以针对端侧ai的应用场景,对混合专家模 型进一步微调优化,使其与多种端侧任务适配,推动端侧ai的推理效率。
(本文仅供参考,不代表我们的任何投资建议。如需使用相关信息,请参阅报告原文。)





